|
Yisheng He is a researcher at Alibaba. He obtained his Ph.D. at HKUST, advised by Prof. Qifeng Chen, Prof. Long Quan, and Dr. Jian Sun. Email / Google Scholar / GitHub 🔥 We are now actively hiring research interns. The successful candidates will conduct research to publish at leading international conferences. To apply, please email your CV to: ethanheysh@gmail.com. |

|
|
I'm interested in 3D Computer Vision, AIGC, Embodied AI, and Digital Avatar. ( * denotes equal contribution; ^ denotes intern student; ✉ denotes corresponding author.) |
|
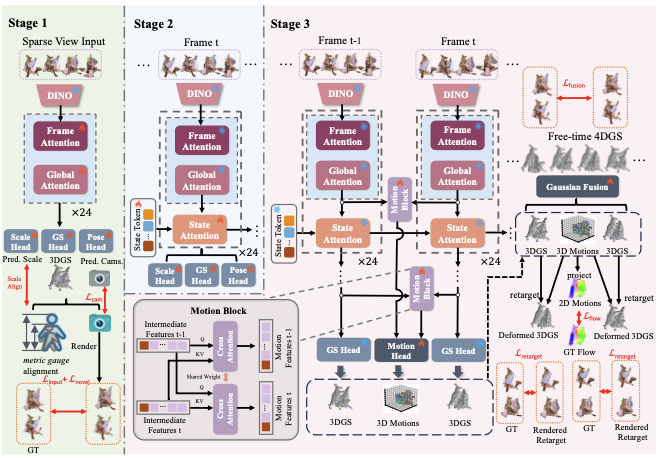
Yingdong Hu*^, Yisheng He*✉, Jinnan Chen, Weihao Yuan, Kejie Qiu, Zehong Lin, Siyu Zhu, Zilong Dong, Jun Zhang Preprint, 2025 project page / paper / code 
Forge4D is the first feed-forward model for 4D human Gaussian reconstruction in real world metric scale, and enables novel-view and novel-time synthesis from uncalibrated sparse-view videos in an efficient streaming manner. |

|
Peng Li*^, Yisheng He*✉, Yingdong Hu^, Yuan Dong, Weihao Yuan, Yuan Liu, Siyu Zhu, Gang Cheng, Zilong Dong, Yike Guo Preprint, 2025 project page / paper / code PanoLAM is a large avatar model for Gaussian full-head reconstruction from a single unposed image. It utilize coarse-to-fine and dual-branch frameworks that creates Gaussian full-head within a second. |

|
Ruohao Zhan*, Yijin Li*, Yisheng He, Shuo Chen, Yichen Shen, Xinyu Chen, Zilong Dong, Zhaoyang Huang, Guofeng Zhang ACMM, 2025 paper CoProSketch provides prominent controllability and details for sketch generation with diffusion models. |

|
Yisheng He*, Xiaodong Gu*, Xiaodan Ye, Chao Xu, Zhengyi Zhao, Yuan Dong, Weihao Yuan, Zilong Dong, Liefeng Bo SIGGRAPH, 2025 project page / paper / code 
LAM creates animatable Gaussian heads with one-shot images in a single forward pass, which can be reenacted and rendered on various platforms (including mobile phones) in real time. |
|
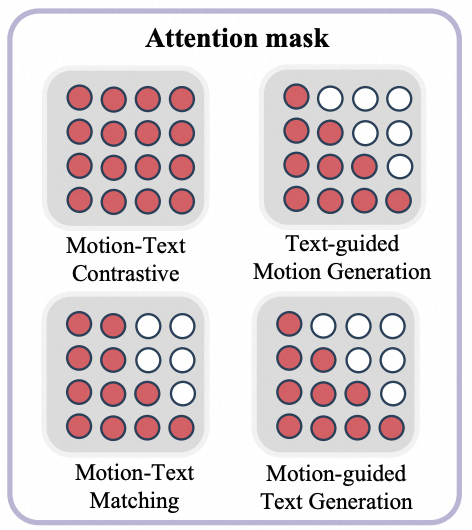
Zhe Li^, Weihao Yuan, Yisheng He, Lingteng Qiu, Shenhao Zhu, Xiaodong Gu, Weichao Shen, Yuan Dong, Zilong Dong, Laurence T. Yang ICLR, 2025 project page / paper / code 
LaMP is a language-motion pretraining model that advances text-to-motion generation, motion-text retrieval, and motion captioning through aligned language-motion representation learning. |
|
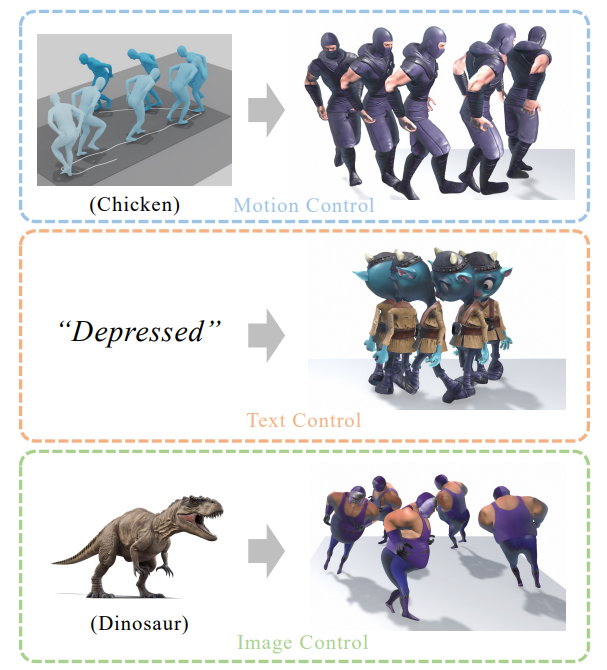
Zhe Li^, Yisheng He, Zhong Lei, Weichao Shen, Qi Zuo, Lingteng Qiu, Shenhao Zhu, Zilong Dong, Laurence T. Yang, Weihao Yuan Arxiv, 2025 paper We build a bidirectional control flow between the style and the content for stylized motion generation and enable multimodal style control including text, image, and style motions. |
|
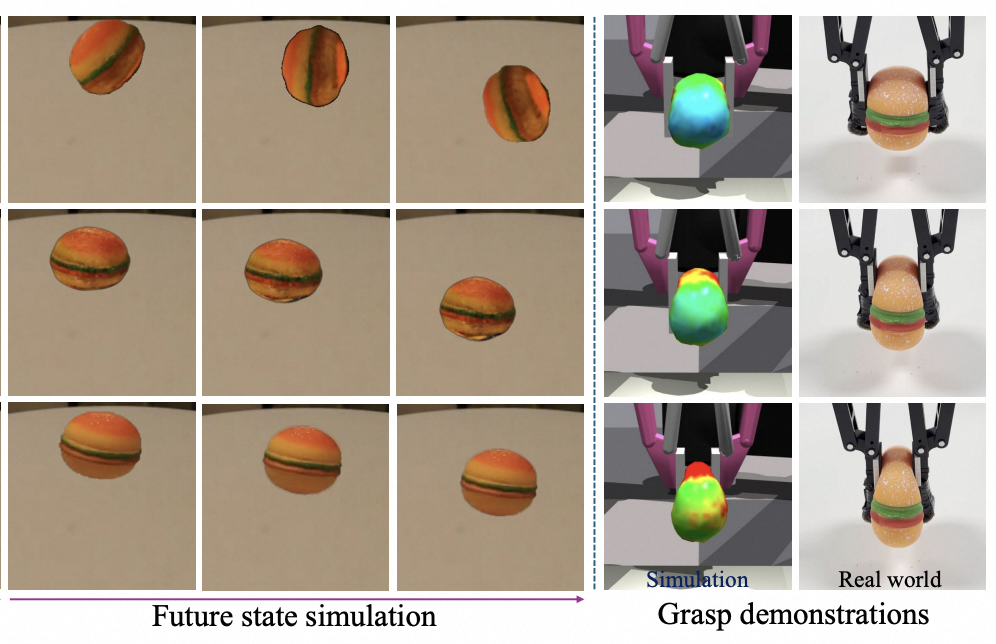
Junhao Cai^, Yuji Yang, Weihao Yuan, Yisheng He, Zilong Dong, Liefeng Bo, Hui Cheng, Qifeng Chen NeurIPS, 2024 (Oral Presentation) project page / paper / code 
We introduce a hybrid framework that leverages 3D Gaussian representation to advance physical property identification. |
|
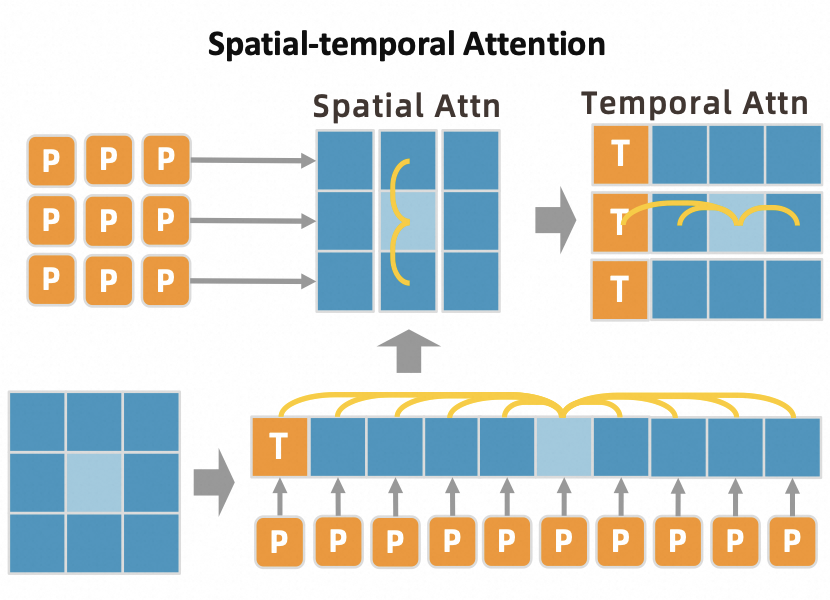
Weihao Yuan*, Yisheng He*, Weichao Shen, Yuan Dong, Xiaodong Gu, Zilong Dong, Liefeng Bo, Qixing Huang NeurIPS, 2024 paper We introduce a 2D joint VQVAE to quantize each joint instead of all joints into tokens. A spatial-temporal modeling framework with temporal-spatial 2D masking and 2D attention is also proposed for motion generation. |

|
Yisheng He, Weihao Yuan, Siyu Zhu, Zilong Dong, Liefeng Bo, Qixing Huang ECCV, 2024 project page / paper We enable high-fidelity, transferable, and intensity control for neural field editing. |

|
Minglin Chen^, Longguang Wang, Weihao Yuan, Yukun Wang, Zhe Sheng, Yisheng He, Zilong Dong, Liefeng Bo, Yulan Guo Arxiv, 2024 paper Our method synthesizes consistent 3D content with fine-grained sketch control. |
|
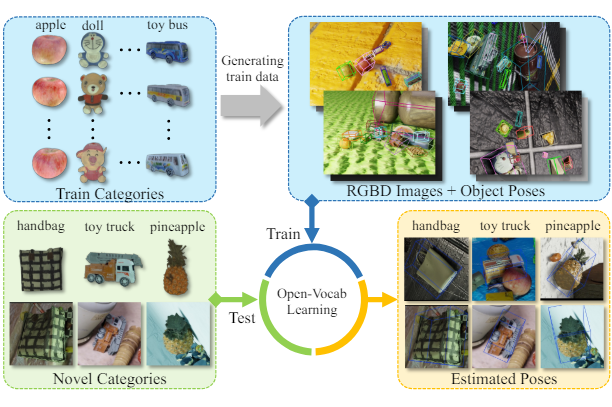
Junhao Cai*^, Yisheng He*, Weihao Yuan, Siyu Zhu, Zilong Dong, Liefeng Bo, Qifeng Chen, IEEE Robotics and Automation Letters (RA-L), 2024 project page / paper / code 
We introduce a new problem: open-vocabulary 9D object pose and size estimation, a new dataset: OO3D-9D, and a new framework based on vision foundation model to tackle this problem. |
|
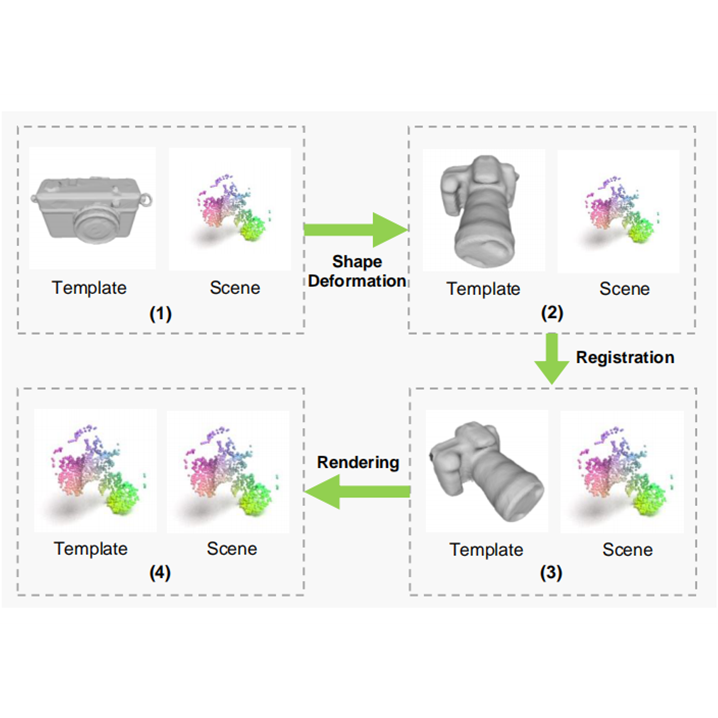
Yisheng He, Haoqiang Fan, Haibin Huang, Qifeng Chen, Jian Sun Arxiv, 2022 project page / paper A self-supervised framework for category-level object pose and size estimation via differentiable shape deformation, registration, and rendering. |

|
Yisheng He, Yao Wang, Haoqiang Fan, Jian Sun, Qifeng Chen CVPR, 2022 project page / paper / data / code 
A new open-set few-shot 6D object pose estimation problem: estimating the 6D pose of an unknown object by a few support views without CAD models and extra training. A large-scale synthesis dataset for pre-training and benchmarks for future research. |
|
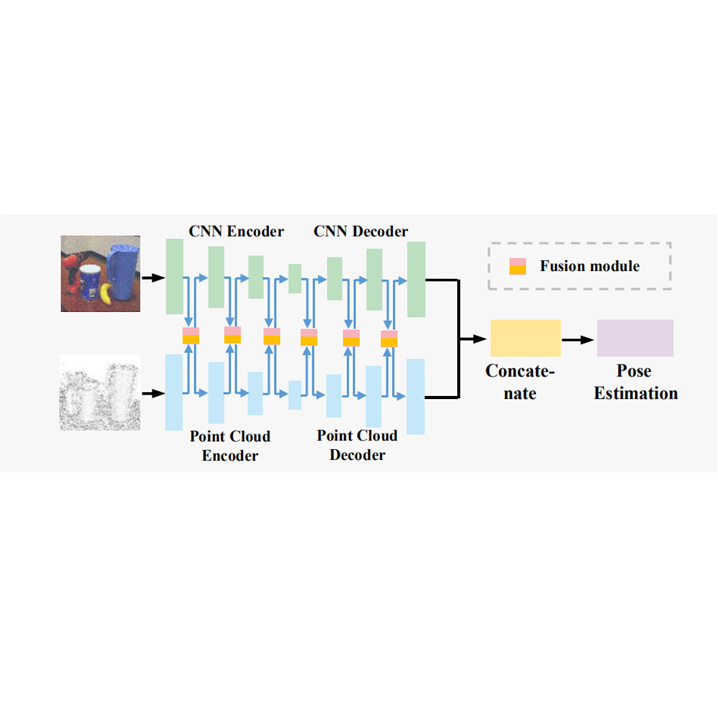
Yisheng He, Haibin Huang, Haoqiang Fan, Qifeng Chen, Jian Sun CVPR, 2021 (Oral Presentation) project page / paper / code  /
video (youtube) /
video (bilibili) /
video (youtube) /
video (bilibili)
A generic full flow bidirectional fusion framework for RGBD representation learning, applied to joint instance semantic segmentation and 3D keypoint-based 6D pose estimation. |
|
Lei Yang, Ziwei Yan, Yisheng He, Wei Sun, Zhenhang Huang, Haibin Huang, Haoqiang Fan arXiv, 2021 project page / paper / code / dataset A brand new dataset to promote the study of instance segmentation for objects with irregular shapes and an affinity-based algorithm to tackle it. |

|
Yisheng He, Wei Sun, Haibin Huang, Jianran Liu, Haoqiang Fan, Jian Sun CVPR, 2020 project page / paper / code  /
video (youtube) /
video (bilibili) /
video (youtube) /
video (bilibili)
The first deep learning 3D keypoint-based 6D pose estimation algorithm and an overall framework for joint instance semantic segmantation and 3D keypoint detection. |
|
|

|
|
|
|
|
Last updated: October, 2025. Thanks Dr. Jon Barron for sharing the template code. |